DeepSeek V3.1 发布后,一则官方留言让通盘这个词 AI 圈齐震憾了:
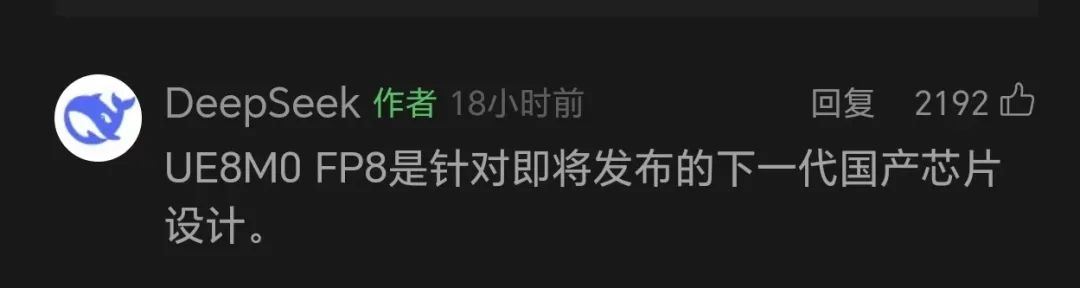
新的架构、下一代国产芯片,悉数短短不到 20 个字,却蕴含了宏大信息量。
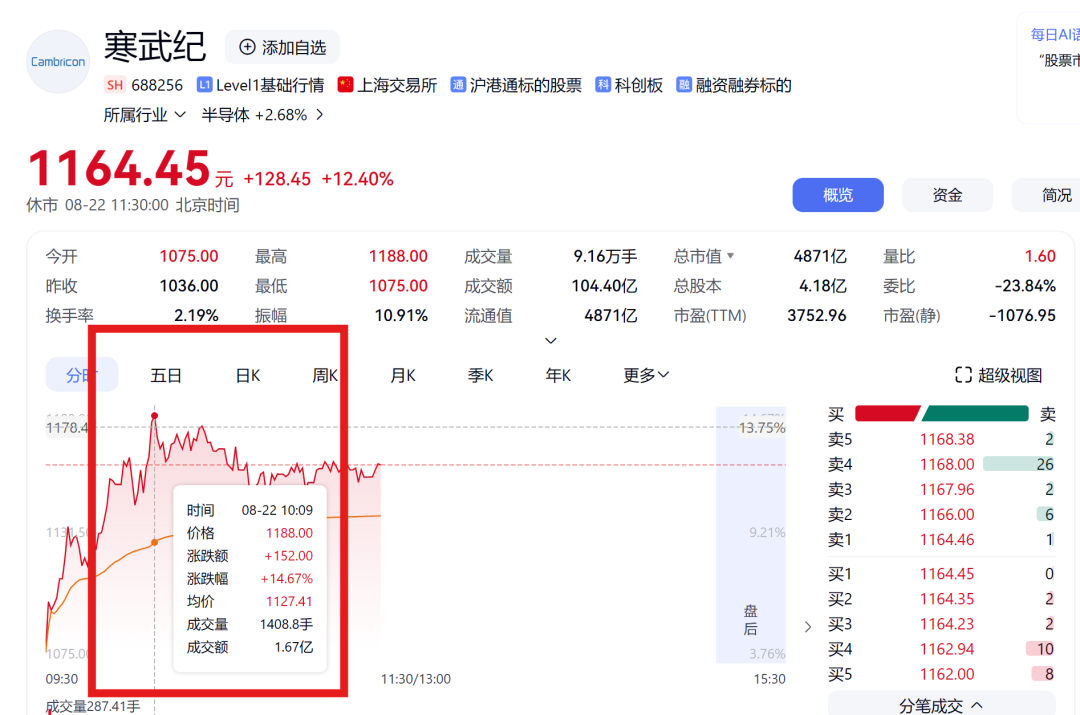
国产芯片企业股价也跟风高潮,比如寒武纪当天早盘盘中大涨近 14%,总市值跃居科创板头名。
半导体 ETF,相似亦然在半天的时辰里大涨 5.89%。(不知说念算作放出音书的 DeepSeek 背后公司幻方量化,有莫得趁便炒一波【手动狗头】)
这个 UE8M0 FP8 到底是个啥?下一代国产芯片,又是指什么?
相继而来的疑问,挤爆了东说念主们的大脑。

在知乎上,也有不少大神驱动边科普边分析我方对这件事的认知。
咱抱着学习心态,不妨就从 UE8M0 FP8 的观点驱动提及。
什么是 UE8M0 FP8?
“UE8M0 FP8”这个观点,不错拆分红前后两个部分来施展,前边的 UE8M0,是 MXFP8 旅途里的“缩放因子”。
MXFP8 是 Open Compute Project 在 2023 年发布的《Microscaling (MX) Formats Specification v1.0》里界说的 8 bit 微缩块要领。
Open Compute Project 是 2011 年由 Facebook(现 Meta)结伙英特尔、Rackspace 等发起的开源硬件互助磋议,主张是通过分享数据中心及办事器联想鼓舞行业完毕提高。
其成员声势尽头强盛,外洋还有微软、谷歌、亚马逊、AMD、英伟达等,而国内的阿里、腾讯、百度等也参与其中。
说回 MXFP8,它以 FP8 为基础成就,FP8 是把惯例浮点要领压缩到 8 bit 的一种编码形态。
MXFP8 的中枢念念想是先把张量切成固定长度的“块”,然后为每个块单独指定一个 2 的整数次幂算作“缩放因子”,把块内所特等全部除以这个系数后再写成 FP8。
这种块级(而不是全张量级)的缩放,让 MXFP8 既保留了 8 bit 位宽,又把可用动态范围扩张了几十倍。
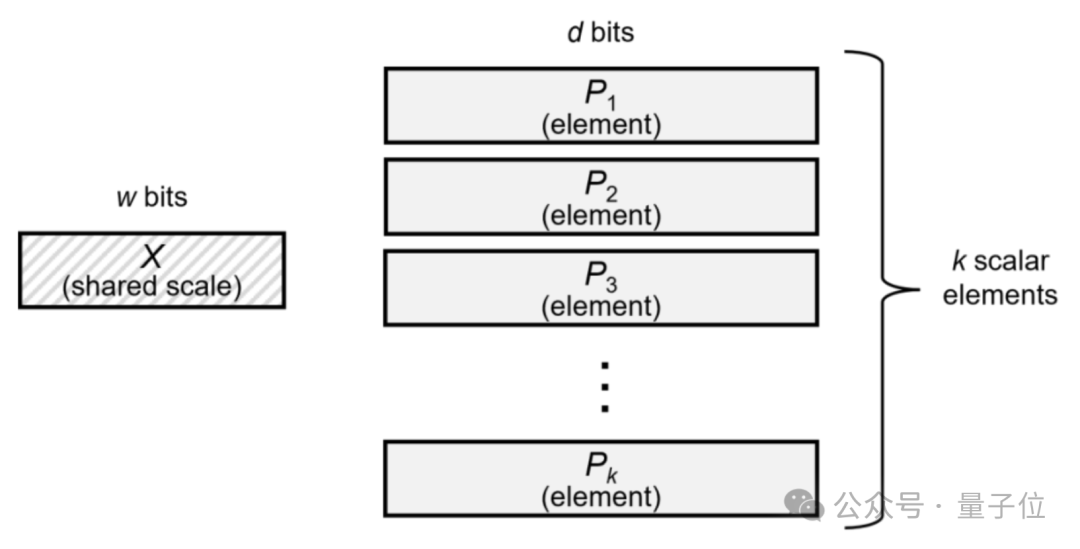 ▲ 来源英伟达时期博客
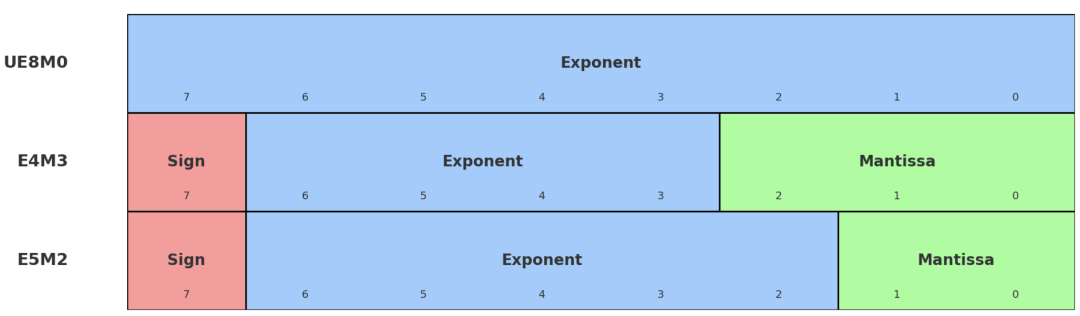
▲ 来源英伟达时期博客而这里的“缩放因子”亦然包含 8 个 bit,其中包含象征位、指数位和余数位,开荒者不错自行将这 8 个 bit 分派给这三种不同的位。
其中象征位只永别有无,若有则占一个 bit,无则不占用,而 UE8M0 中的 U 暗示的即是无象征(有象征可暗示为 S 或概略不写)。
E 和 M 则分别暗示指数位和余数位分派到的 bit 数,E8M0 指的即是 8 个 bit 澈底分派给了指数位。
其他常用的要领还有 E4M3、E5M2(缩放绪论外的践诺部分也常选择这两种)等,它们均包含象征位,其余 7 个 bit 在指数和余数位之间分派。
DeepSeek 之前开源的 5.6k 星标式样 FP8 GEMM 内核 DeepGEMM 就也曾撑握 UE8M0,不外这个式样主如果适配英伟达芯片和 CUDA 生态。
那么,选择这种全指数暗示缩放因子的形态,有什么克己呢?
着手,由于 UE8M0 不含余数与象征位,处理器在字据缩放因子对数据进行还原时,只需要乘以对应的 2 的幂,也即是挪动一下指数位,而不需要浮点乘法、规格化或舍入逻辑,贬抑了时钟关节旅途。
何况 UE8M0 的动态范围覆盖 2^(−127) 到 2^128,其指数表可应答容纳这一跨度,为后续块缩放提供填塞空间。
另外 UE8M0 还能处置单范例 FP8 无法同期顾及大 / 小值,导致溢出或被压成 0 的问题,将 UE8M0 算作分块的范例后,诞妄率弧线从整张弧线下落到一条远低水平的横线,在保握 8 bit 张量精度的同期大幅减少信息蚀本。
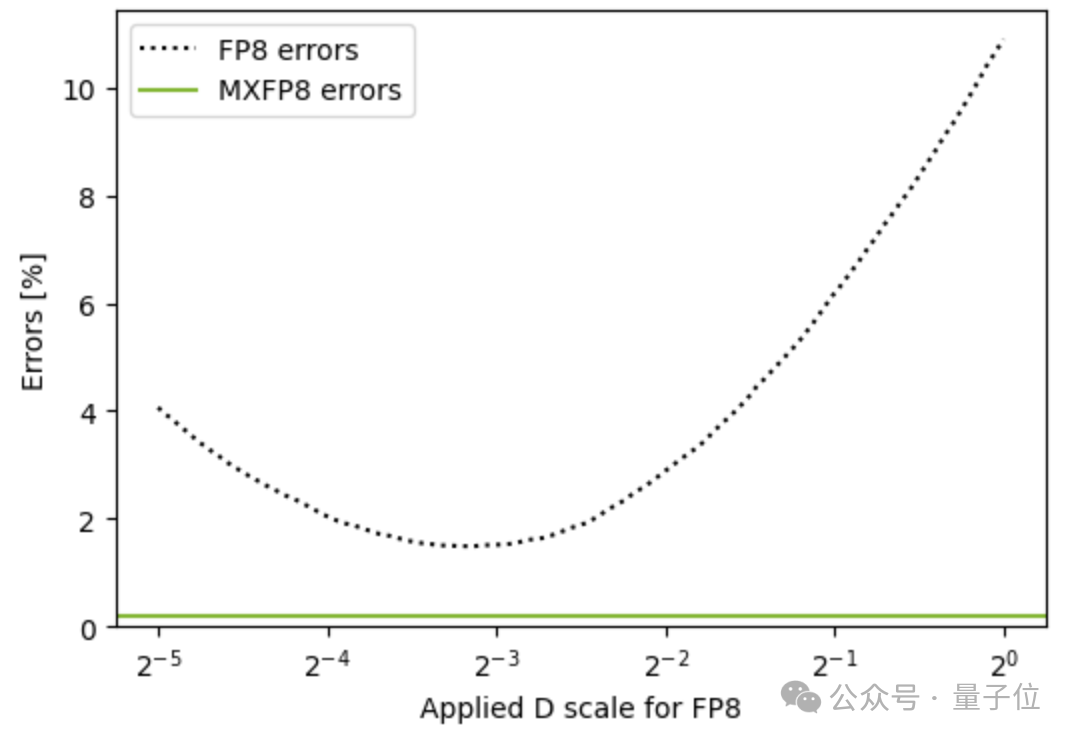 ▲ 来源英伟达时期博客
▲ 来源英伟达时期博客UE8M0 FP8 的克己咱们了解了,当今不错施展为什么它更适配“下一代国产芯片”了。
大部分已量产的国产 AI 加快器仍沿用 FP16 / BF16 + INT8 的盘算通路,并未集成 E4M3 / E5M2 这类完满的 FP8 乘加单位。
不外,摩尔线程 MUSA 3.1 GPU、芯原 VIP9000 NPU 等 2025 H2 首发的新款国产芯片也曾在宣传良友里列出“原生 FP8”或“Block FP8”撑握,并与 DeepSeek、华为等 15 家厂商结伙考据 UE8M0 要领。
天然下一代国产芯片天然也曾在为 FP8 作念出准备,但 HBM / LPPDDR 带宽仍然与顶尖芯片存在较大差距。
而 UE8M0 让一组 32 个 FP8 数据只追加 8bit 缩放绪论,比拟传统的 4B(32bit) FP32 缩放平直知人善任 75% 的流量,这种空间知人善任步调被视作下一代架构的伏击优化主张。
DeepSeek 为哪个国产芯片作念了优化?
在搞明晰啥是 UE8M0 FP8 之后,回过神来的网友们又驱动纷繁想到:
DeepSeek 这是在说哪一家的国产芯片呢?
在官方有益卖关子的情况下,东说念主们只好着手把视力放在了首批通过“DeepSeek 大模子适配”的 8 家厂商。
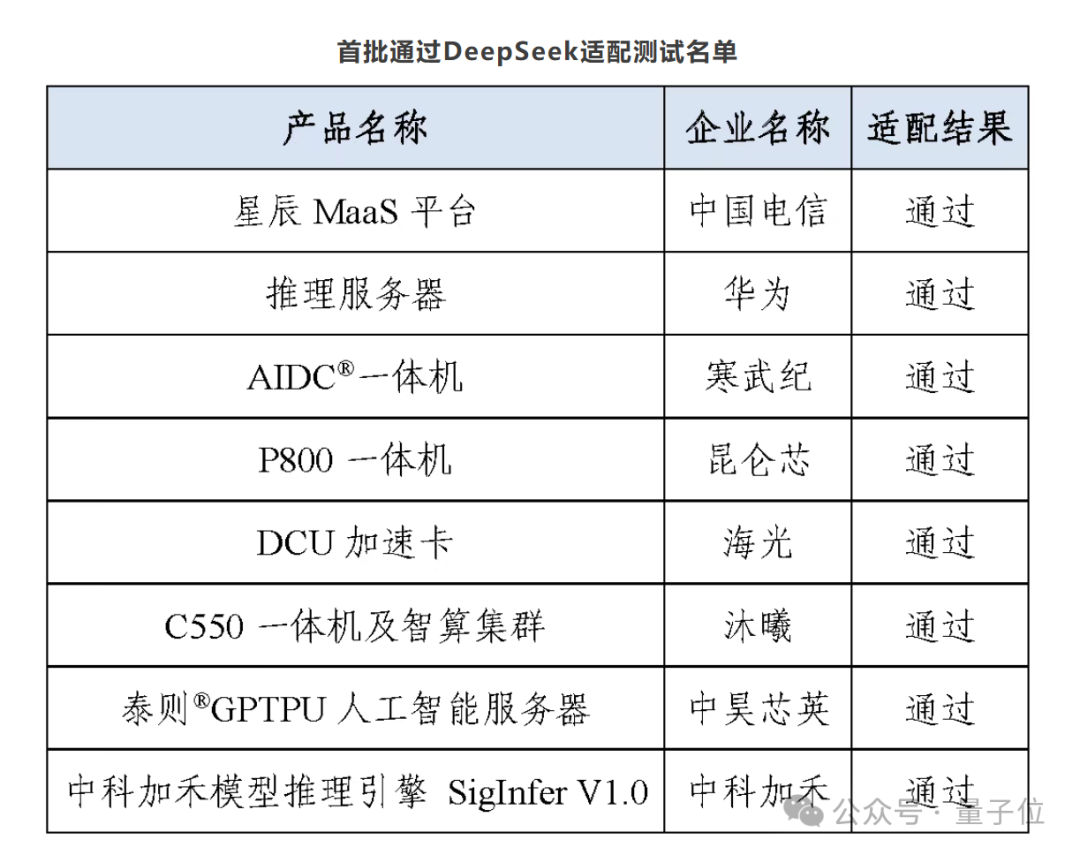 ▲ 来源中国信通院官微
▲ 来源中国信通院官微这当中各人看好的“头号种子选手”当属寒武纪,市集响应尽头直不雅 ——
抑止当天 10:25,寒武纪盘中大涨近 14%,总市值超 4940 亿元,越过中芯国际跃居科创板头名(践诺以最新为准)。
事理也很肤浅,该公司旗下的 MLU370-S4、念念元 590 及最新 690 系列芯片均撑握 FP8 盘算,在架构联想和低精度盘算优化上一直相对比较最初。
而基于雷共事理,海光、沐曦,中昊芯英以致包括名单除外的摩尔线程等也齐被网友们挨个点名:
海光:其深算三号 DCU 撑握 FP8 盘算,存在进一步优化的空间;
沐曦:本年 7 月发布的曦云 C600,也撑握 FP8 精度盘算;
中昊芯英:其“一瞬”TPU AI 芯片撑握 FP8 精度;
摩尔线程:算作国内少许数原生撑握 FP8 的 GPU 厂商,旗舰家具 MTT S5000 撑握 FP8 精度盘算。
与此同期,一些很有可能“行将上车 FP8”的厂商也出当今了一众清点名单中。
举例华为昇腾,天然昇腾 910B 和 910C 暂不撑握原生 FP8,但官方道路图也曾写明“2025Q4 原生 FP8”,是以世东说念主瞻望或将在 2026 年推出的 910D(可能的定名)很有可能是所谓的“下一代芯片”。
除了以上这些,还有一大串芯片厂商的名字出当今了磋议当中,号称盛况空前。
天然猜来猜去莫得最终定论,但不妨碍市集给以强烈回报。字据最新音书,当天国产芯片观点集体高开,科创 50 大涨 3% 创近三年半新高,芯片产业链集体走强。

是以,各人为什么集体狂欢?这些国产芯片一朝撑握 UE8M0 FP8 究竟意味着什么?
综合现时国表里各方说法来看,一切齐不错用一句话来笼统:
这代表了国产 AI 正走向软硬协同阶段,简略实质性减少对英伟达、AMD 等外洋算力的依赖。
这里头的逻辑也很肤浅清澈,恰是由于 UE8M0 FP8 精度要领所具备的上述上风(更小的带宽、更低的功耗、更高的隐隐),这意味着相似的硬件今后能跑更大的模子,是以国产芯片的“性价比”被大幅拉高了。
换句话说,这些国产芯片厂商将在竞争中更具上风,因此也就属于利好了。
从另一方面来看,DeepSeek 通过更动精度要领,尽头于主动贴合国产芯片的最好性能点,这种软硬协同的模式无疑是把国产芯片们拉进了一个调和的生态坐标系。
这就像畴昔的“Wintel 定约”一样 —— 微软和英特尔通过深度时期绑定,筑起了个东说念主盘算机领域的生态护城河,只不外如今换成了 DeepSeek 和国产芯片厂商们。
One More Thing
事实上,官方在正文部分提到 UE8M0 FP8 的唯有一句话:
需要详确的是,DeepSeek-V3.1 使用了 UE8M0 FP8 Scale 的参数精度。
而且位置尽头“笼罩”,藏在了一大段行云活水的功能更新先容之后。

要不是官方专诚在批驳区补了一句,想到各人还没啥嗅觉。
是以你说它这个动作吧,不知说念算不测照旧刻意为之,总之是尽头微妙了 (手动狗头)。
参考鸠集:
[1]https://www.zhihu.com/question/1941891000319580108
[2]https://www.zhihu.com/question/1941882763503473149/answer/1942093625908524069
[3]https://docs.nvidia.com/cuda/nvmath-python/0.3.0/tutorials/notebooks/matmul/04_fp8.html
[4]https://www.ainvest.com/news/deepseek-ue8m0-fp8-optimization-rise-china-sufficient-ai-stack-2508/
本文来自微信公众号:量子位(ID:QbitAI)开云体育,作家:克雷西、一水,原标题《DeepSeek 一句话让国产芯片集体暴涨!背后的 UE8M0 FP8 到底是个啥》
告白声明:文内含有的对外跳转鸠集(包括不限于超鸠集、二维码、口令等体式),用于传递更多信息,知人善任甄选时辰,完毕仅供参考,IT之家通盘著作均包含本声明。 ]article_adlist--> 声明:新浪网独家稿件,未经授权谢绝转载。 -->